European Journal for Biomedical Informatics is an online journal publishing submissions in English language, which is devoted towards the progress in biomedical science. The journal welcomes all types of research communications through its rational open access window to maximize the possibilities of global reach for each article. The frequency of issue release is bi-annual, and strictly supported by peer-review process. The primary aim of the journal is to make all the information's freely available irrespective of different socio-economic barriers, which further will help in the progress of science. Moreover, the journal intends to showcase all the timely research information on biomedical informatics and its related studies for the effective contribution in the field of biomedical methods and technologies.
European Journal for Biomedical Informatics is dealing with a range of topics which is included under the scopes of biomedical informatics. The focus of the journal is on the major aspects of implementation of information science in Medical sciences, which includes Biomedicine, Biometrics, Health informatics, Medical informatics, Clinical informatics, Dental Informatics, Semantics Interoperability, Ontology, Medical devices, Informatics applications in Imaging, Telemedicine/Telehealth, Artificial intelligence in healthcare. Such key topics and associated plenty of sub-topics are the scope of the journal. Certainly, quality and standard are the major issue on which the journal emphasizes most. The research articles of the journal are exceptionally high standard in terms of fact and ethical considerations. The journal put forwards the strict concern for accuracy and authenticity of the communicated article before all nominal need of the journal.
Original contribution in terms of research, review, short-communication, case reports, are welcomed from the authors, who are engaged in medical or academic research. The articles selected for publication, must have to go through critical process of peer-review as per journal norms. A well-constructed editorial board is the higher most determining authority for the journal, which is formed by highly experienced subject experts in the field of biomedical informatics. Section editors and guest editors are also engaged there to maintain topic specific proper evaluation of research manuscripts.
European Journal for Biomedical Informatics encourages researchers to submit relevant research works within the scope of the journal. To submit manuscripts, authors can use our Online Manuscript Submission System or can send their manuscripts directly to our Editorial Office at biomedicalinformatics@scholargatherings.com .
Publication Ethics and Publication Malpractice Statement
This journal follows the guidelines of the International Committee of Medical Journal Editors (www.icmje.org) and the Committee on Publication Ethics (www.publicationethics.org).
Fast Editorial Execution and Review Process (FEE-Review Process):
This journal is participating in the Fast Editorial Execution and Review Process (FEE-Review Process) with an additional prepayment of $99 apart from the regular article processing fee. Fast Editorial Execution and Review Process is a special service for the article that enables it to get a faster response in the pre-review stage from the handling editor as well as a review from the reviewer. An author can get a faster response of pre-review maximum in 3 days since submission, and a review process by the reviewer maximum in 5 days, followed by revision/publication in 2 days. If the article gets notified for revision by the handling editor, then it will take another 5 days for external review by the previous reviewer or alternative reviewer.
Acceptance of manuscripts is driven entirely by handling editorial team considerations and independent peer-review, ensuring the highest standards are maintained no matter the route to regular peer-reviewed publication or a fast editorial review process. The handling editor and the article contributor are responsible for adhering to scientific standards. The article FEE-Review process of $99 will not be refunded even if the article is rejected or withdrawn for publication.
The corresponding author or institution/organization is responsible for making the manuscript FEE-Review Process payment. The additional FEE-Review Process payment covers the fast review processing and quick editorial decisions, and regular article publication covers the preparation in various formats for online publication, securing full-text inclusion in a number of permanent archives like HTML, XML, and PDF, and feeding to different indexing agencies.
Select your language of interest to view the total content in your interested language
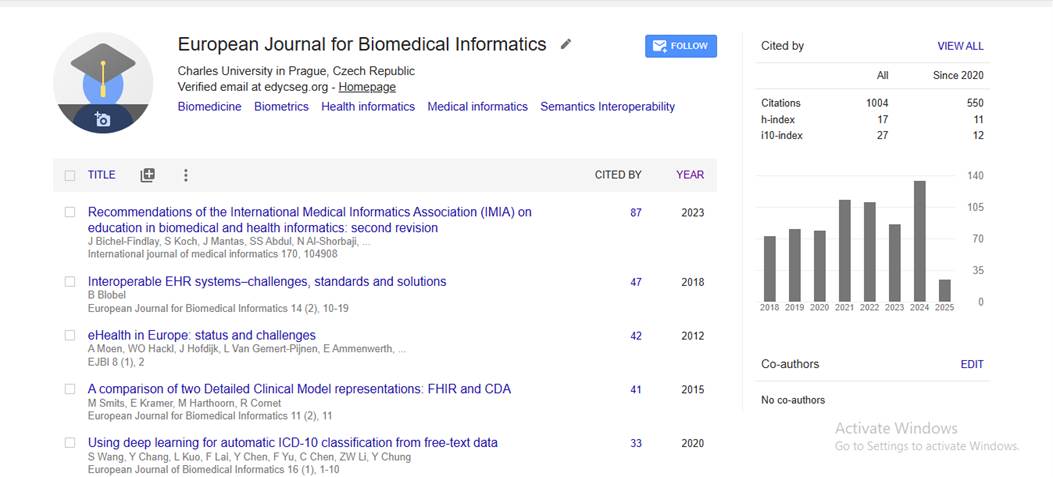
European Journal of Biomedical Informatics received 1004 citations as per google scholar report